

Machine Learning o aprendizaje automático, es un concepto en boga y que no deja indiferente absolutamente a nadie, y es que este brinda un sinfín de ventajas a nuestras estrategias, procesos y toma de decisiones utilizando para ello uno de los activos estratégicos más importantes de las organizaciones, los datos.
En este post, nos adentraremos en este mundo, definiendo sus conceptos principales y respondiendo a una de las preguntas más espontáneas e importantes que surgen de parte de nuestros clientes: ¿Cómo puedo aplicar machine learning a mi estrategia digital? Para ello vamos a comenzar definiendo qué es machine learning.
Machine Learning o Aprendizaje Automático ¿Qué es?
El aprendizaje automático es un área de la inteligencia artificial que permite que las computadoras y los sistemas informáticos aprendan de manera similar a como lo hacemos las personas. El objetivo principal de estos algoritmos, es que las computadoras adquieran conocimiento y vayan mejorando la realización de tareas y el análisis de datos para los que han sido destinados sin recibir una programación explícita para ello.
Dentro de las ventajas que brinda el machine learning podemos mencionar algunas como:
- Mejor focalización en clientes de valor para el negocio, esto nos permitirá una mayor precisión de nuestras estrategias al estar entregando a nuestros clientes lo que necesitan en el momento que lo necesitan.
- Mayor ahorro de costos a corto, mediano y largo plazo a través de la optimización de procesos a lo largo de la organización.
- Además nos permitirá tomar mejores decisiones basados en datos.
Otra pregunta importante que surge de nuestros clientes es: ¿cómo es que los algoritmos aprenden a tomar decisiones por sí mismos? y ¿Qué tipo de acciones concretas pueden realizar nuestros modelos?
Los modelos de machine learning aprenden con datos, mientras mayor cantidad y más variados los datos, mejor. Idealmente debemos rescatar estos datos desde múltiples fuentes que van desde sistemas de la organización, datos abiertos, redes sociales, encuestas, logs de información, etc. Dentro de los tipos de aprendizaje más comunes que ocupan estos modelos para tomar decisiones, existen 2 tipos, el aprendizaje supervisado y el aprendizaje no-supervisado.
En el aprendizaje supervisado, el algoritmo aprende a través de un conjunto de datos que posee una etiqueta final o variable target, la cual conocemos y viene en los datos. El objetivo principal de este tipo de entrenamiento, es poder determinar la variable target a partir de nuevos datos en el futuro.
Por el contrario, en el caso del aprendizaje no-supervisado, solamente tenemos variables predictoras, es decir, no tenemos una variable target para supervisar lo que el modelo aprende o bien es un número infinito de etiquetas, por lo que nosotros mismos debemos indicar un número de etiquetas, para que el mismo modelo sea capaz de encontrarlas por sí mismo.
Dentro de las tareas específicas que nos permite realizar el aprendizaje automático están:
- Clasificación: Consiste en determinar una clase o categoría determinada a partir de un conjunto de clases finitas, ejemplo: Buen cliente, Mal cliente. Cuando la clasificación tiene sólo 2 clases, se le llama clasificación binaria; cuando tiene más de 2 clases o categorías, se le llama clasificación multiclase. La clasificación utiliza técnicas de aprendizaje supervisado.
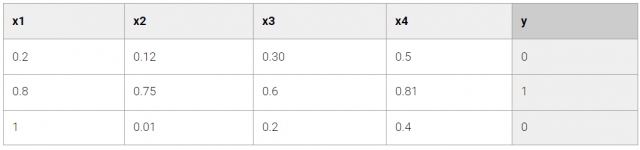
Tabla 1: Clasificación Binaria
En Tabla 1, podemos apreciar 2 tipos de columnas, los predictores, con los atributos x1, x2, x3 y x4 y la variable target, en el atributo y. La idea es que a partir de los predictores, se pueda determinar la variable target para futuras entradas de datos.
- Regresión: A diferencia del ejemplo anterior, en el cual queríamos predecir una categoría, cuando hacemos una regresión, lo que queremos estimar es un valor numérico. Uno de los ejemplos más claros para explicar esto, es la predicción del clima para una ciudad y fecha determinada. Las regresiones también utilizan técnicas de aprendizaje supervisado. En la Tabla 2, se puede observar un ejemplo de Regresión.
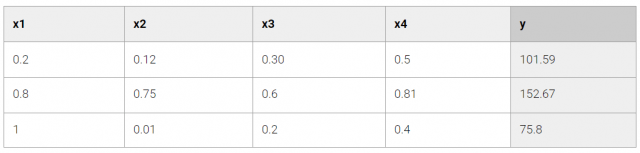
Tabla 2: Regresión
- Clustering: Las técnicas de clustering, consisten en ser capaz de agrupar datos, solamente con variables predictoras, es decir, sin tener una variable target. Este tipo de algoritmos, utilizan el tipo de aprendizaje no-supervisado.
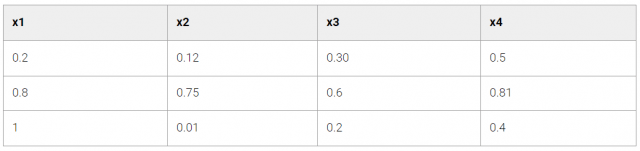
Tabla 3: Agrupamiento
En la Tabla 3, podemos observar que en el conjunto de datos solamente tenemos las variables predictoras x1, x2, x3 y x4, y la variable target, ya no existe.
¿Cómo aplicar Machine Learning en Marketing Digital?
Las aplicaciones de machine learning en estrategias de marketing digital son bastante diversas y se centran principalmente en las interacciones de los clientes con el negocio. Estas interacciones la mayoría de las veces implican sesiones, compras, búsquedas, y otras acciones de valor. Podemos decir que dentro de las estrategias más relevantes utilizadas en el mundo del marketing digital, podemos encontrar las siguientes:
1.1. Customer Lifetime Value
Customer Lifetime Value o Valor del Tiempo de Vida de un Cliente, desde ahora (CLTV), hace referencia a un pronóstico sobre cuál es el retorno esperado de nuestros clientes para nuestra empresa en los próximos períodos, es decir, es el valor que un cliente contribuye al negocio durante su vida útil, a partir de su primera compra, contrato o conversión.
El hecho de poder definir el valor del tiempo de vida del cliente, nos ayudará a dar respuesta a preguntas como las se mencionan a continuación:
- ¿Son nuestro clientes rentables en el largo plazo?
- ¿Estamos invirtiendo los suficientes recursos en fidelizar y agradar a los clientes según su CTLV?
- ¿Qué estrategias debemos tener de cara al futuro para mejorar su fidelización con nuestra marca?
El CLTV puede ser calculado de muchas maneras, una de ellas es utilizando Machine Learning.
1.2. Predicción de Churn Rate
Otro ejemplo muy referenciado a la hora de hablar de aplicaciones de Machine Learning en Marketing Digital es el análisis de Churn Rate o Fuga de Churn. El Churn rate es, en otras palabras, la tasa de abandono o baja de un servicio de nuestros clientes.
Para las empresas (sobre todo en las de telecomunicaciones), es importante que los clientes no abandonen los servicios contratados, ya que es mucho más caro adquirir nuevos clientes, que retener clientes antiguos.
Para paliar este problema, las empresas crean modelos de machine learning para predecir la probabilidad de fuga de clientes y así poder retenerlos a tiempo.
1.3. Customer Segmentation
Además, es posible segmentar a nuestros clientes a partir de distintos parámetros que se pueden establecer a partir del comportamiento de los usuarios, por ejemplo, comportamiento de compra, o preferencias de ciertas categorías de productos. También puede ser a partir de datos demográficos como por ejemplo la edad, lugar de residencia, género, etc.
Esto nos permite definir clusters para, por ejemplo, generar mensajes o gráficas diferenciadas en un e-commerce o dar determinado descuento a cierto segmento por sobre otros.
1.4. Sentiment Analysis
También, podemos analizar los comentarios que dejan los clientes sobre los productos o servicios que entrega nuestra organización. Esto se hace a través de una puntuación basada en un bloque de texto.
Esta puntuación puede ser positiva, negativa o neutra. Utilizando técnicas de machine learning, se puede analizar este sentimiento al ingresar el bloque de texto que se desea interpretar.
¿Hay más aplicaciones? Por supuesto que sí, sin embargo y para efectos de este post, se seleccionaron las más relevantes.
Otra pregunta frecuente que nuestros clientes realizan es qué infraestructura se puede utilizar para realizar esta labor. La verdad es que no existe una respuesta 100% correcta a esta pregunta y depende mucho del tipo de negocio y objetivos de negocio que se tienen, pero se recomiendan las siguientes:
2.1. Almacenamiento
Google Cloud Platform, posee herramientas que permiten desde el guardado de ficheros, pasando por almacenamiento de bases de datos (SQL y NoSQL) para apps, hasta el almacenamiento de grandes data-warehouses o data-lakes. Dentro de las más recomendadas herramientas de almacenamiento de datos, están Bigquery y Cloud SQL. Ahora bien, si necesitamos almacenamiento de archivos, se recomienda el uso Google Cloud Storage.
2.2. Análisis, Exploración de Datos y Testeo de Modelos
Para labores referidas al análisis, exploración de datos, creación y testeo de modelos predictivos, se recomienda Google Cloud Datalab.
Cloud Datalab permite explorar, visualizar, analizar y transformar los datos de manera interactiva y sencilla mediante lenguajes familiares, como Python, R y SQL.
2.3. Modelos Preconstruidos
GCP también nos ofrece modelos preconstruidos para que nuestro trabajo sea menor. Dentro de las plataformas que ofrecen están:
- NLP API: Api para procesamiento de lenguaje natural. Nos permite, por ejemplo, hacer sentiment analysis.
- Speech-to-Text API: Para la conversión de voz a texto.
- Translation API: Para traducción de texto en diferentes idiomas.
- Vision API: Para el procesamiento de imágenes.
Ahora que ya conoces esta información, y sabes que es infalible en cualquier estrategia de Marketing Digital, ¡estás a un mensaje de implementarlas con el equipo de Mentalidad Web!
¡No olvides activar las notificaciones de nuestro blog y así enterarte de lo último sobre marketing digital en Chile y el Mundo!
Además, puedes visitar nuestro Canal de Youtube y ver el Webinar completo sobre Machine Learning junto a Fernando Saavedra.







